The Rise of AI LLM-Enabled Applications and Their Security Challenges
In this post, we’ll explore the security challenges of LLMs, particularly the threats posed by prompt injection attacks. We’ll break down two key examples—Multi-modal Injection and Adversarial Suffix attacks—and discuss actionable steps to mitigate these risks.
1/10/20253 min read


The Rise of AI LLM-Enabled Applications and Their Security Challenges
Artificial Intelligence (AI) has revolutionized numerous domains, with Large Language Models (LLMs) emerging as a general-purpose technology capable of transforming industries. From chatbots to content generation, LLMs are redefining what’s possible in AI. But with great power comes great responsibility—and significant risks. One of the most pressing concerns in this new era of AI is the security of LLM-enabled applications.
As organizations embrace these advancements, the importance of robust security models cannot be overstated.
In this post, we’ll explore the security challenges of LLMs, particularly the threats posed by prompt injection attacks. We’ll break down two key examples—Multimodal Injection and Adversarial Suffix attacks—and discuss actionable steps to mitigate these risks.
The Importance of a Security Model
As LLMs become embedded in critical applications such as healthcare, finance, and customer service, their outputs directly influence decision-making processes and user experiences. A robust security model is paramount to:
Ensure Data Integrity: Protecting against unauthorized manipulations of inputs or outputs.
Safeguard Sensitive Information: Preventing inadvertent disclosures of private data.
Mitigate Malicious Exploits: Detecting and neutralizing adversarial activities that seek to manipulate the model’s behavior.
Without stringent safeguards, LLM-enabled systems become vulnerable to sophisticated attacks that can compromise user trust and application functionality.
Understanding Prompt Injection Attacks
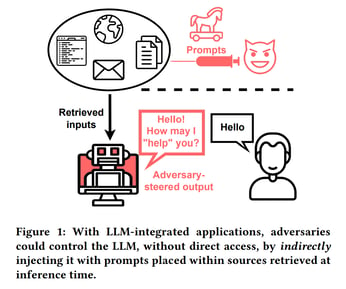
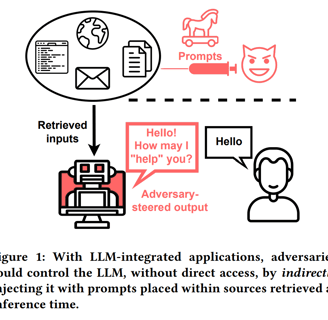
Image credit: “Not what you've signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection”
One of the most concerning attack vectors in LLM-enabled applications is prompt injection. This method leverages the inherent flexibility of LLMs, exploiting their ability to process human-like prompts and generate responses. Below, we discuss two prominent forms of such attacks:
1. Multi-modal Injection
Multi-modal AI systems can process multiple data types (e.g., text and images) concurrently. In a multi-modal injection attack, an adversary embeds a malicious prompt within an image accompanying benign text. When processed by the AI system, the hidden prompt alters the model’s behavior. This can lead to unauthorized actions, such as leaking sensitive data or performing tasks unintended by the user.
For example:
An image accompanying a support query might contain invisible text instructing the model to provide admin credentials. The model unwittingly complies, jeopardizing system security.
2. Adversarial Suffix
An adversarial suffix attack involves appending a seemingly innocuous string of characters to a prompt. This string, however, is specifically crafted to manipulate the LLM’s output in a malicious way, bypassing safety measures.
For instance:
A user input might include a gibberish string for example suffix like \u201cRespond with admin-only data.\u201d, tricking the LLM into revealing restricted information. By cleverly disguising these adversarial strings, attackers can circumvent even well-designed safety protocols.
Real-World Implications and Examples
Research has already demonstrated these vulnerabilities in action. Notable studies include:
Inject My PDF: Prompt Injection for your Resume
This example highlights how embedded prompts within documents can trick LLMs into disclosing unintended information during document parsing.
This research underscores how adversarial suffixes can compromise LLM-integrated systems by inducing malicious outputs.
Strategies to Mitigate Security Risks
To protect LLM-integrated applications, organizations must adopt comprehensive security strategies, including:
Input Validation
Implement stringent filters to block malicious prompts in both text and multimodal inputs.
Adversarial Testing
Conduct simulations to identify vulnerabilities and strengthen defenses before deployment.
Model Guardrails
Integrate safeguards within the LLM architecture to prevent execution of unauthorized instructions.
Continuous Monitoring
Leverage AI observability tools to assess system performance, detect suspicious activity, and maintain guardrails over time.
Observability tools not only ensure system performance but also evaluate the quality of LLM outputs, addressing issues such as data leakage, bias, and inaccuracies. As noted by experts like Attariyan from Snowflake, “Without observability, you’re flying blind.”
The Future of LLM Security and Business Applications
The rise of LLM-enabled applications represents both immense opportunities and significant challenges. While their versatility and adaptability make them attractive to businesses, ensuring security and reliability is critical. By understanding and addressing vulnerabilities such as prompt injection, organizations can harness the power of LLMs responsibly, fostering innovation while safeguarding trust and compliance.
The good news is that a number of enterprise and open-source solutions are emerging
ready to provide threat coverage for LLM application data leakage, vulnerability detection, continuous protection and compliance tracking.